Building your own ORM... and other Bad Ideas

- foxtrotzulu94
- Jan. 21, 2018
The Tacoma Narrows Bridge prior to its collapse on November 7th, 1940
Since the start of the year, I’ve kept myself busy outside of work with non-coding projects. I’ve read through Fabien’s Sanglard’s excellent “Game Engine Black Book: Wolfenstein 3D”, watched the 1st part of Fate Stay Night: Heaven’s Feel in theatres and even got around to playing Halo 3 on my Xbox One after setting up my home network again with OpenWRT. But last week I was even busier as work picked up and, at home, I went back to rewriting some of my old code for an ongoing project which has a deadline coming up soon.
If the first thing that went through your head was: “man, why are you rewriting your old code? Do you enjoy needlessly redoing work?”, I can tell you, I didn’t plan for this the first time around. Any competent software developer is taught why they don’t want to be rewriting old code. It becomes a time sink and what you thought would take only a couple of weeks might end up taking months or years and costing your company/department/team everything! Only extreme cases ever merit it, and it’s only done in isolated/re-factored sub-components of a larger system. The foundations, mostly, stay in place. Doing it on entire large scale, production systems is a proven recipe for disaster. In short, the bottom line is: “if it ain’t broke, don’t fix it”
But I think this specific case merited a rewrite. This wasn’t a large-scale system, but it grew complex only by our inexperience. Writing it from scratch is probably quicker than tracking down all the obscure bugs that we swept under a rug as deadlines were looming over us. It’s also an opportunity for me to ensure that the project can be handed off to someone else who can develop new features and not be bogged down by the shortcomings of the previous implementation. But, personally, I’m rewriting my old code because I wasn’t satisfied with the way something I did came out in that project. As you might have guessed, it had to do with rolling your own ORM (and learning a thing or two along the way). This is a pretty long post full with heavy technical details. But I hope it's worth the read.
Some Context
Before diving deep into the world of databases, applications and caffeine-fueled ideas, there’s some context needed to grasp the issue at hand. The project I’m referring to in this post is my final year Engineering Design Project (Capstone). The Capstone project my team chose had a simple but non-trivial goal in mind: detect the risk of injury in athletes. Our system would do that through the use of cutting edge technology in cameras and an analysis method we’d implement by “reverse engineering” existing studies on early injury detection. Our three people team dubbed the project the “Kinetic Intelligent Tracking System” (KITS, for short) and it was (unofficially) under way on September 1st, 2016.
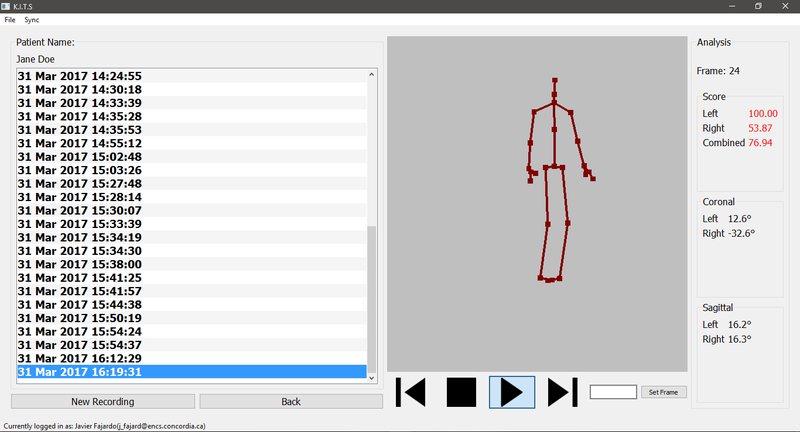
The finalized KITS application reviewing a recording and estimating 100% probability of an ACL injury on the user's left knee
While I won’t discuss intricate details of the project, I will state the basic facts. We chose to write it from scratch in C++ for performance considerations. Among many of the requirements that had been set was the ability to keep track of a basic “Hospital” system: there are doctors, they have patients and patients have recordings associated to them (but recordings cannot have identifiable patient data anywhere). This project course would also share in its planning with other more traditional engineering methodologies, so we were forced into a Waterfall Model throughout the project. Lastly, while not a hard requirement, we were heavily encouraged to rely on as little external code as possible. We all interpreted that to mean that our final grade would be inversely proportional to the amount of libraries/frameworks the project relied on. We were already using libraries for the more complex parts of our project, so we’d thought we’d have a hard time justifying an ORM library on top of that.
So, as we completed the design phase and began implementing persistency into our application during December, I remember saying: “Guys, I think we can build our own ORM code, it should only take me a couple of days.” There were more reasons behind this statements than just being naive and some of it included features we promised at the time (but ultimately couldn't deliver on). I volunteered and so a nightmare of a feature began. The actual system wouldn’t be ready and functional until the last days of February 2017.
But, wait, What’s an ORM?
In case you’ve never heard about it before, an “ORM” is short for Object-Relational Mapping. ORM systems are used to provide a two-way map between objects in your program and a (generally, SQL) database backend. These systems are provided as a library or as part of a larger framework and are a way of storing data while maintaining your objects and their interdependencies as they go between the database and the device memory.
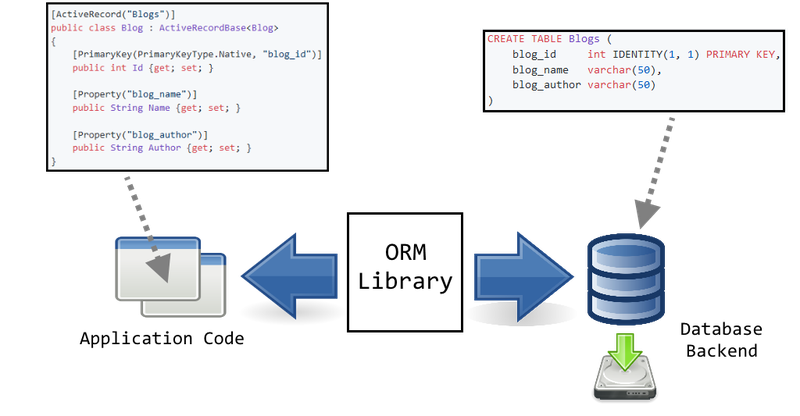
An ORM sits between your application and a database backend. Above, you can see how a "Blog" class might look like in C# and in SQL (Derived work - Credit: dracos, GNOME Icon artists - CC BY-SA 3.0)
Since often the abstract constructs and data structures a programmer relies on cannot be easily translated to a relational database paradigm, ORMs place some restrictions on how the data can be composed. These restrictions are embodied by the schema of the relational database. A good ORM will generally make schema creation and migrations painless and, sometimes, automatically. But no ORM can completely abstract the operations that occur underneath it. When things go south, it pays to know SQL well or risk losing all the data stored.
Recently, I hear less and less about ORMs being used. There seems to be some resentment towards SQL and ORMs in general as NoSQL systems and Document-oriented Databases (like MongoDB and CouchDB) have become commonplace. But, ultimately, ORMs remain a stable method of introducing persistent storage to an application. And if you’re thinking about using SQL in some form or another, you might as well do so through an ORM to avoid repetitive work. Many of the libraries and frameworks that implement an ORM usually have strong guarantees on consistency and some might be just plain easy to use out-of-the-box.
ORMs and C++
Before attempting to write my own ORM for this project, I did do some research into existing solutions. I wasn’t that crazy or too keen on writing the system from scratch, even after having volunteered. I had worked with ORMs before and knew a handful of them for Java and Python. I knew that for these languages ORM libraries aren’t hard to find. A quick search will show hundreds of implementations and you’ll also see the more established ones will have some port written for PHP, C# and other languages. But, in comparison, there seemed to be very few results for C++. And restricting to the ones that were open-source seemed to yield almost no results.
Our misguided conclusion was that we could dedicate sufficient time to build something just the right size for us and avoid integration problems and bugs down the road. But, not finding an adequate ORM library for C++ should’ve been a red flag from the start. The fact that there was no equivalent in C++ to, say, Hibernate in Java or SQLAlchemy in Python was a good indication of the appropriateness of the language for building such a system. My guess, as I’ll explain further below, is that C++ lacks a Type Introspection (Reflection) system which can be useful for supporting translation between types in memory and tables in a database.

Reflection, what C++ lacks (Image by The Photographer - Source - CC BY-SA 4.0)
{kind=link}
A House of Cards
I started building the ORM system about a week after volunteering for the task. We had about 6 classes that would need to be stored in a database and only one of them had an actual inheritance tree to keep intact. "Simple enough", I remember saying. We had already agreed on using sqlite3 as a means of a local database and writing some code on top of the SQLite library for this system. To have a good functioning ORM we needed to have at least four SQL commands in place: “INSERT”, “SELECT”, “UPDATE” and “DELETE”; these form the basis of any persistent storage and are referred to (sometimes jokingly) as CRUD.
I started by building the thin abstraction layer on top of the sqlite library to be used by our code. I took the “sqlite_amalgation” source and incorporated it directly into our project. Initially, we'd interface with the “sqlite3_exec” function and build the various SQL query strings by formatting the input to the Insert, Update, Query and Delete methods. These methods all received a table name and a pointer to a “string_map” instance, the latter of which was just a structure holding key value pairs that corresponded to column names and the row values. From there, it was relatively straightforward to build a string for the corresponding command with the right information inside.
std::shared_ptr<TransactionResult> SQLite3Provider::Insert(std::string table, string_map * values)
{
std::stringstream statementBuff;
string_map::combination combo = values->Linearize();
statementBuff << "INSERT INTO " << table <<" (";
size_t columns = combo.ordered_keys.size();
//Loop through all of the columns
for (int i = 0; i < columns; ++i) {
if (i != 0) {
statementBuff << ",";
}
statementBuff<<combo.ordered_keys[i];
}
statementBuff << ") VALUES (";
//Loop through all of the data that will make up the rows
for (int i = 0; i < combo.ordered_values.size(); ++i) {
if (i != 0) {
statementBuff << ",(";
}
auto& list = combo.ordered_values[i];
for (int j = 0; j < columns; ++j) {
if (j != 0) {
statementBuff << ",";
}
statementBuff << "\""<<list[j]<<"\"";
}
statementBuff << ")";
}
std::string statement = SanitizeInput(statementBuff.str());
LastQuery = statement;
bool isGood = ExecuteStatement(statement, &(SQLite3Provider::InsertCallback), this);
std::shared_ptr<TransactionResult> retVal = std::shared_ptr<TransactionResult>(new TransactionResult());
retVal->ResultState = isGood? TransactionResult::SUCCESSFUL : TransactionResult::UNSUCCESSFUL;
retVal->TableName = table;
return retVal;
}Our Insert function showing the query string creation. Note that "string_map" is a specialized std::unordered_multimap<std::string, std::string> and "string_map::combination" is a type that flattens the data into indexed arrays
Because we were using C++, had the sqlite library building from source and really supported few classes in our ORM, we were not at all worried about the inefficiency of creating query strings every time we interacted with the database. This also had the side effect that we could take the same string and run in it SqliteStudio and see what the effect was (which was great for debugging!). But the flip-side was that we were wide open against SQL injections and could maybe only mitigate some cases. Allowing this in any production system would’ve been reckless (at best).
std::string SQLite3Provider::SanitizeInput(std::string statement)
{
//HACK: THIS IS NOT A BULLETPROOF WAY OF SANITIZING INPUT
// This should be changed to something different or extensively test
std::vector<std::string> inputs = Split(statement, '\\');
inputs = Split(inputs[0], ';');
if (inputs.size() > 1) {
//Warn
GetLog()->warn("Detected possible SQL Injection with statement \'{}\'", statement);
}
return inputs[0];
}We were able to detect a fraction of trivial SQL injection strings this way. It was supposed to be a temporary solution but we never moved to a permanent fix. It's a good thing this was never to be released
Granted, this is horrible. We told ourselves it was Ok because it was a temporary solution. And it did have a straightforward fix: move to prepared statements in sqlite. I was ready to do that once the system was functional. But there was a bigger problem in the implementation of our ORM: we can put a “string_map” into our database, but how do we make our classes into string_maps? Furthermore, how do we teach our database the schema we’re using in our application? Here’s where I realized I had built a house of cards waiting to fall in our faces as our project was beginning to seriously fall behind schedule. Being in the last semester, everyone on the team also had to deal with, at least, three other class projects in parallel. Not to mention midterms and regular class work. Time was the scarcest resource.
My fix for the schema problem was simple: make the schema beforehand as an SQL script and include it in the build process as a resource. During the first run, execute the schema script and prep the sqlite database. For development, we’d check if the schema version in code was higher than the one in a special database table, and run the newer script if it was. This essentially nuked the database on every schema update, completely avoiding migrations between versions. Would we ever migrate if we released this? Probably not and we were not going to release it. Problem Solved.
As for turning class instances into “string_map” objects, there was no easy fix. We needed to grab each instance, read all the declared fields (public, protected and private) and then read the value of each field. The easiest way would be to do it at runtime, but recall that C++ doesn’t support complicated Type Introspection. At most, you can know if two classes are related or not through RTTI. Even getting the base class is compiler-dependent. MSVC uses the “super” keyword, it has been considered in the ISO C++ committee, but hasn’t been standardized. We desperately needed reflection and were short on time. I doubled down on our mistake and decided to implement a basic reflection system myself as well. This was another bad idea, and two wrongs definitely don't make a right.
Every class that interacted with our ORM inherited from the "PersistentObject" abstract class and was required to implement certain methods that would be used to inspect the type for mapping to and from the database. To save objects, each class would build the string_map internally and wrap it in a “StorageUpdate” class so the ORM could reference the abstract PersistentObject and update its state. Along with that, each class had to “report” any associations it might have so those tables in the database could also be updated if necessary. Loading an object instance was done via a special constructor in which classes would receive a dictionary containing the entire information of their class hierarchy. In the constructor, each class checks the value their name maps to and is able to query the resulting data structure for all of its fields. This is done in the order in which the constructors are called in a class hierarchy, so subclasses can rely on base classes having been built successfully.
Experience is the Best Teacher
The ORM we implemented, as described in the previous section, has a ton of flaws. Tightly coupling the classes and the ORM system and requiring these classes to expose information about themselves through overloaded functions, is almost the epitome of un-maintainability. Countless times this lead to silent bugs resulting from classes being changed but their methods for loading and saving remaining untouched. Similarly, the rigidity created by the makeshift-Reflection system and the handmade ORM schema meant we didn’t stop seeing bugs until we cut our persistent classes to three and stopped introducing changes to them. We had to freeze that section of our code to achieve stability.
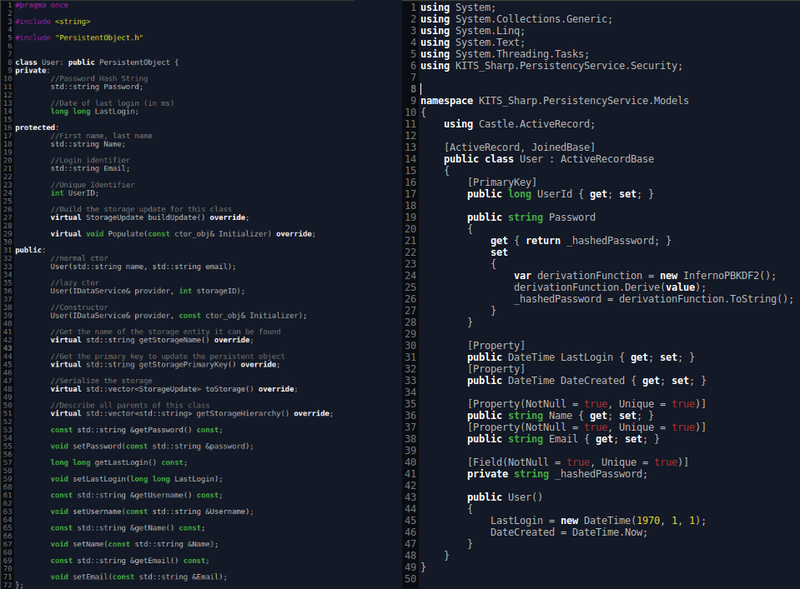
The "User" class in KITS. To the left is the C++ header file. The 100 line source file is excluded for brevity. To the right is the full implementation for the C# rewrite using the Castle.ActiveRecord ORM. It is just shy of 50 lines
It was hard to barely finish that ORM on time. We sunk way too much time that shifted away from the primary focus of our project and killed our momentum when the other pieces began to require the persistent storage system to be active. This was definitely a complex endeavour that could’ve easily been a Software Engineering Capstone project of its own. But, honestly, even if I was doomed from the start, by building that ORM I grew a lot as a developer. At the very least, I learned that Ted Neward makes a hell of a point for anyone thinking about rolling their own ORM. But, ultimately, there are good, mature open-source ORMs now that can be easily reused. So, as Martin Fowler wrote, a lot of hate on ORMs may be unwarranted.
Lessons Learned
It's not too often that we get to reflect on mistakes we made a long time ago. Rewriting part of my project gave me a chance to remember what I did, see what I've learned since then and (hopefully) look to make better decisions in projects that might come in the future. From this experience, there are three important things I learned that I wanted to share:
-
To code is human... but to reuse, DIVINE. If you find something and you’re legally allowed to reuse it, do it. Whatever time was put into it is time you won’t have to put in yourself. Even if it’s frustrating to configure, you’ll likely get it up and running before the time it takes to replicate the same features.
-
If you know you made a mistake, and there’s no way out, learn as much as you can. You’re already in for a rough ride: long nights, tons of coffee and probably a lot of debugging; there's no getting out of that. But it would be even worse to accept it as is and not reflect on it (pun intended). There's a bad tendency in any new project for things to happen again out of inexperience or forgetfulness. So, grow wiser and spot these pitfalls early on.
-
Meta-programming for the win. Before building an ORM, meta-programming seemed esoteric to me. But there’s no denying that the use of macros, templates and reflection is extremely powerful for development. I’m pretty sure Rust macros are a good reason why the Redox project has been developing so fast. So the next time you find yourself writing repetitive code, see if you can make code to write your code.
Conclusion? You can definitely learn a lot from bad ideas and from re-inventing the wheel in your personal projects. Just... maybe don't do it on a deadline.